Web Scraping with Browser development console & javaScript
After pulling the data from an API ans displaying it in a web page Chart, and developing a crude selection list for different countries and dates, I started to think about creating my own API as a project.
As I looked around for data I came across Dixon Cheng’s Github repository of Covid-19 data scraped from the MoH’s website and in JSON format. So I can play with that rather than relying on my Excel Scraping. So that will allow me to revisit what I’ve done already.
On reviewing my Google Sheets importXML() and Excel get from Web I wondered if I could do that in JavaScript. Then when asking Mr YouTube up pops all these packages with JQuery & React etc. I only wanted to use native JS as it doesn’t break when you neglect it and you don’t have to bloat your server with packages to stop them breaking when updating (still an issue when browser won’t read older stored code packages).
Then, I saw this cool video , this is real raw and I love it, a bit manual, but I love its simplicity:
I really like this simple solution so I will explore trying to capture information from the MoH site. This is my next project.
I tried to set up the process in Firefox Dev tools, but could only get XPath, and I needed to copy JS Path and so I had to use Chrome browser to do that.
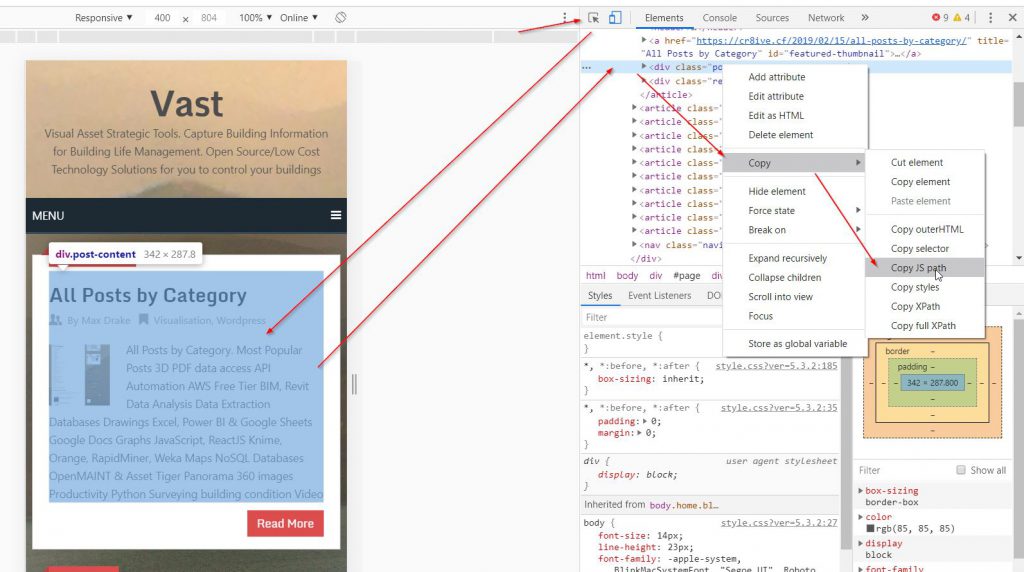
Also, when I built up the script to extract information it as follows: document.querySelector(“#content > article:nth-childs2) > header > h2”) it has the code at the front of it document.querySelector.
Also, for the actual code, after identifying the element we want to extract data from it, so it becomes document.querySelector(“#content > article:nth-childs2) > header > h2”).innerText and in the video he adds innerText (also could use innerHTML) so what is returned is ext. As this is pulling numbers from the table it is returning an array with only TEXT. So the numbers aren’t usable in that form .
So you need to do some sort of conversion to the returned array. I tried doing document.querySelector(“#content > article:nth-childs2) > header > h2”) .innerText .parseINT() but that didn’t work, but got a partial success with document.querySelector(“#content > article:nth-childs2) > header > h2”) .innerText*1, multiplying the resulting text by 1. This worked on numbers such as “24”, “243” but the numbers in the table were formatted as “1,234” and this just returned Null as it doesnt recognise the comma in the number.
Two thing I can try are: replacing .innerText with .innerHTML and see if that returns a number, the second is to try the parsing before the innerText as document.querySelector(“#content > article:nth-childs2) > header > h2”) ..parseINT(innerText).
I tried both the above suggestions, neither worked. The innerHTML still gave a string, and the parseINT() encapsulation innerHTML or before it with a dot didn’t work.
If getting numbers out of a table is going to be difficult then this may not be a particularly useful tool if there is a whole lot of data manipulation to change type . I’ll do the tests above, but if it’s a major I may not follow it up further.
I thought there was real potential in this method, as I could get the data and add to a JSON object and then use that as data source, there would not be the issue of tables moving on the page, which is an issue with the Excel from Web scrape method.
Using Firefox
You could use firefox and get the Xpath then you need to wrap it : document.querySelector(“XPath from Firefox“).innerText;
Creating an a API
After that I want to look at seeing if I can setup my own API, there is this video below that uses a DataBase and PHP. That is sort of my level of coding so I may try that project after the web scraping one.
What I was thinking of was to have a JSON object held somewhere that I could call to retrieve data.
I’d initially downloaded Dixon Cheng’s repository above to use the JSON data, but found that I could call the file from a JS fech() command if I called the file in its RAW format https://raw.githubusercontent.com/dixoncheng/covid19map/master/data/summary.json and this would return a JSON object.
It is calling all the data, rather than just a portion of the data that I was doing with the John Hopkins API on Github that allows you to pull data from a specific date range, and only a specific country.
Although its not as flexible, for my purposes this method would work fine for small datasets, as you pull it down then create arrays in the date range that you want.
I tried putting it onto my server site and calling it from there with VS Code and live server but I get ” (Reason: CORS header ‘Access-Control-Allow-Origin’ missing). “

But if I put the file on my server and call it from there, with the JSON file on my server also, it works fine and I can reach the array data, which is great.

The solution is to bring the JSON file onto the PC so that I’m calling a local file to set up and test, then move the information onto the server, along with the JSON file. Then its a matter of updating the JSON file if its a time series that is changing.
I tried putting RAW in the URL as per the github for my server site but that did not work either.
The plain solution at this time is to use the GitHub repository to call the info too. Actually, I’m a bit confused now. With the JSON file on my server didn’t need it in raw format, but when I was in Github because there is a lot of other html info on the page you do.