Knime 2. General review with new v3.6.0 update
I have been using Knime for a while. I note I have only written about the Database connections with Knime so far. An updated version (3.6.0) came out this month and I decided to update the programme on my computers. There are a few new features from when I last had a good look at it.
After just working my way through the Weka lessons in the 3 courses, which I was quite impressed by and is a handy resource for Weka. I reflected that Knime’s videos are not that great overall, there are knobs and doodahs in the nodes that I still have absolutely no clue about. Orange’s videos are simple, straightforward and work, I think that is also a great resource and I would like to see them grow as Orange is pretty friendly to use.
Knime’s strength for learning is with its EXAMPLES. Pre-made workflows that you can take, run and then adapt to your need. In them you can learn how they have set-up their nodes and can follow along. I quite like the process as you have something that works, so you save a copy and break it, so you learn how to fix it.
There are a great many examples that you can copy, so pick the area of your interest.
In Knime, there are a mass of Nodes that you can choose from. Unlike Weka & Orange there are a massive amount. There are still nodes that I’d like, that FME has, but the Nodes are developed as per interest groups,and there are a lot of Chemistry and Bio nodes, also a lot of generalised ones and also Machine learning ones too. been thinking of using Knime for Web Scraping and connecting to API’s.
Some beginners Knime Tutorial videos below, but search for others.
https://www.youtube.com/watch?v=ft7Ksgss3Tc&list=PLz3mQ6OlTI0Ys_ZuXFTs5xMJAPKBmPNOf
Knime visualisation with Maps
Very early on I used Knime to show changing conditions over time for buildings on a map.
Knime & connecting to API’s
Of late, I have been thinking of using Knime for Web Scraping and connecting to API’s. In this regard I made an attempt at using Python to connect to Stats.NZ via an API. And have been wondering if I could do something similar in Knime. I can, I found some connectors for REST API’s and am currently playing with those with a variable success to date.
In respect to API’s I found a mention of ProgrammableWeb , a directory of API’s you can connect to in this video:
This gentleman also codes the example he demonstrates later in the video, that I think is pretty great:
These 2 videos drove me to test using Knime with the API for the Stats.NZ site. I may write a bit about that later when I finally get some data that I can use in a meaningful way.
Weka, Orange & Knime Image processing
I was looking at the last course on Weka , the Advanced Data Mining with Weka and there was a lesson on Image Processing. Also loading a package for Weka for this, also with a couple of datasets for Owls/Butterflies and vehicles. I followed the video and got the same results as Weka (around 90%) , then I decided to try the training sets with Orange (100% for both) and then I tried using Knime for Image processing after downloading their examples and also the added nodes relating to Imaging. Not successful at even getting a workflow to date.This demonstrates the cussed side of Knime. I have started a post on this so will not mention it further here.
Knime workflows pros and cons
Pros
- FREE!!
- My first and preferred Data Analytics tool. Because of its extensiveness and versatility.
- A really versatile tool. Lots of nodes, lots of different areas. Machine Learning, Graphs, Maps, Analytics, Data Cleaning, Web connections, Big Data, Databases, etc. Lots of cool tools to play with (if only I had a clue what they all did).
- Once workflow is set-up you just plug the inputs in and press the buttons and get the outputs. More transparent than Excel VBA Macros and formula, as you can check output at each node to see what its output is.
- The examples are a great resource. As the come, they usually work (some of the API ones are not as I do not have an API key to the specific package, but that’s fine, I can choose to apply for one).
- Brute force processes. You can create lots of nodes (that you can group as meta-nodes) to do small, incremental steps that you can test and check at each point. So great for testing and de-bugging.
- A really great thing is that you can test one node
- I have just noticed new Connectors to things like Tableau, Weka, Python, R, Spotfire, Apache Spark etc. It seems the next phase of Data Analytics is cross connection to other Data Analytic tools.
Cons
- Knowledge centre blog is terse. You look up an issue and the Knime team are very brief in their explanation. So it can be very difficult getting information on the problem you have. An example of this is Database connections. I searched for ages on the blogs and got very little information and my post on Knime Database connections is almost as popular as my OpenMaint posts. So getting help when you are in difficulties is tough. Its a free programme and I’m sure the company would prefer paying customers. So that is expected.
- If you can’t figure out how the node needs to work for you, getting information on it can be problematic. So you end up trying a lot of different nodes to see if you can find an alternative solution. I have found I tend to use the “Brute force” method to solve the problem rather than having an elegant solution. I will break it down and use 3 nodes where one would have sufficed. It is usually robust, but inflexible. You then move on to the next challenge and rarely go back and refine the initial solution.
- Use nodes inappropriately and add complexity where its not necessary. In the Rest API process I am getting JSON from the Stats.nz site, but cannot tabulate it with JSON nodes, so I convert to XML so that I can get a table. This is because I cannot get the JSON table to work. Added complexity that is not elegant. Whereas in Python you can usually find an elegant coded solution on StackOverflow. This is the difference with better community support.
- I do notice that I spend a lot of time setting things up. A lot of the nodes do not do what you expect them to do, so you are constantly looking at alternatives and testing lots of different nodes.
- I do find opening for looking at results and looking to reconfigure the nodes a nuisance. It would be great to be able to map a few fast keys to these processes as you are using them repeatedly, and an F6 & F7 are not got locations for fast Key functions, so you are constantly right clicking mouse and selecting. These are one of the most used functions and they are mapped to top/middle of keyboard. Instead of bottom left/right where your fingers naturally rest.
- the BIRT reporting tool can be a bit of a challenge. Just hard work to set-up really, but no worse than other reporting setups I have come across.
- Videos are not that great. I think the Orange ones far surpass the Knime ones.
A couple of my examples
This screenshot is of a simple process I set-up for re-naming (buy concatenating multiple columns) for Asset Tiger Asset database to make the searches easier on the mobile app. I kept on testing the App and re-naming the attributes to make the search easy and efficient. Once I had the process set- up I could fine tune it as required until I got what I wanted. I found it quicker than scripting in Excel.
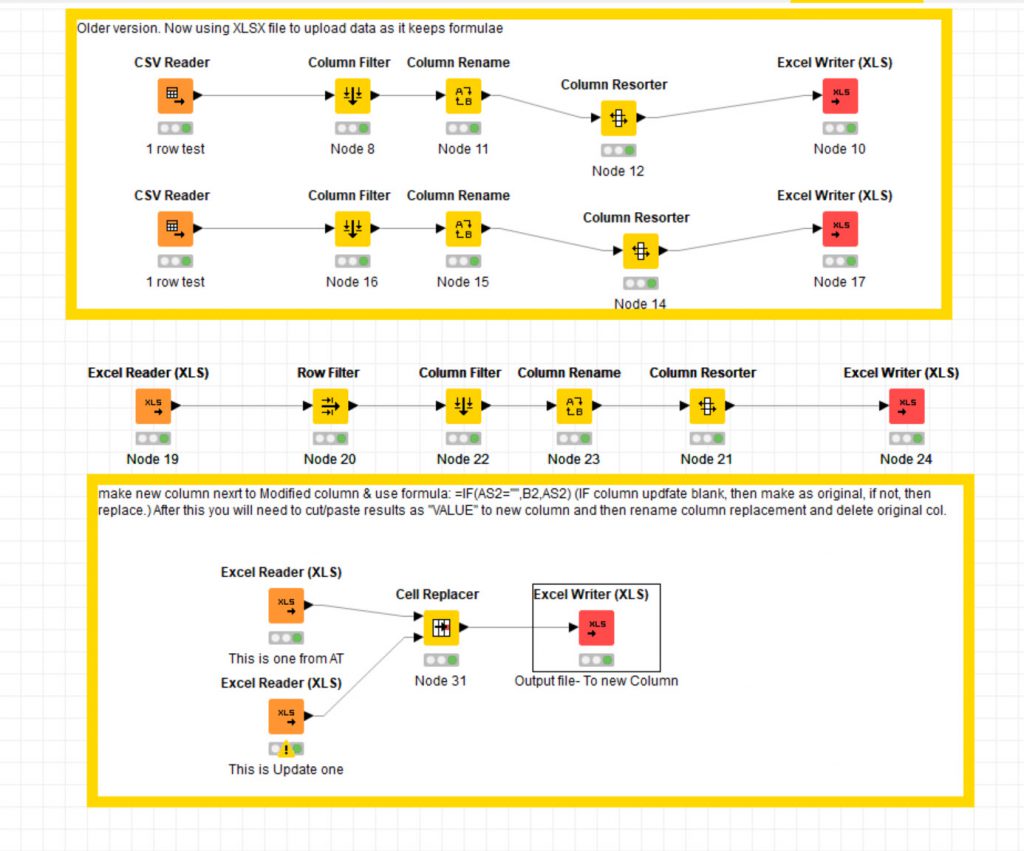
In the large part of the screen you see a Zoomed in element of the overall process shown in the bottom left of the screenshot. This uses meta-nodes (collapsing multiple nodes into one node) so that the process could be run over different elements of the dataset (external roof, walls, doors, windows and internal walls, floor, ceiling, doors, windows, plumbing fixtures, joinery etc) so that you could show a specific elements condition in a specific year.
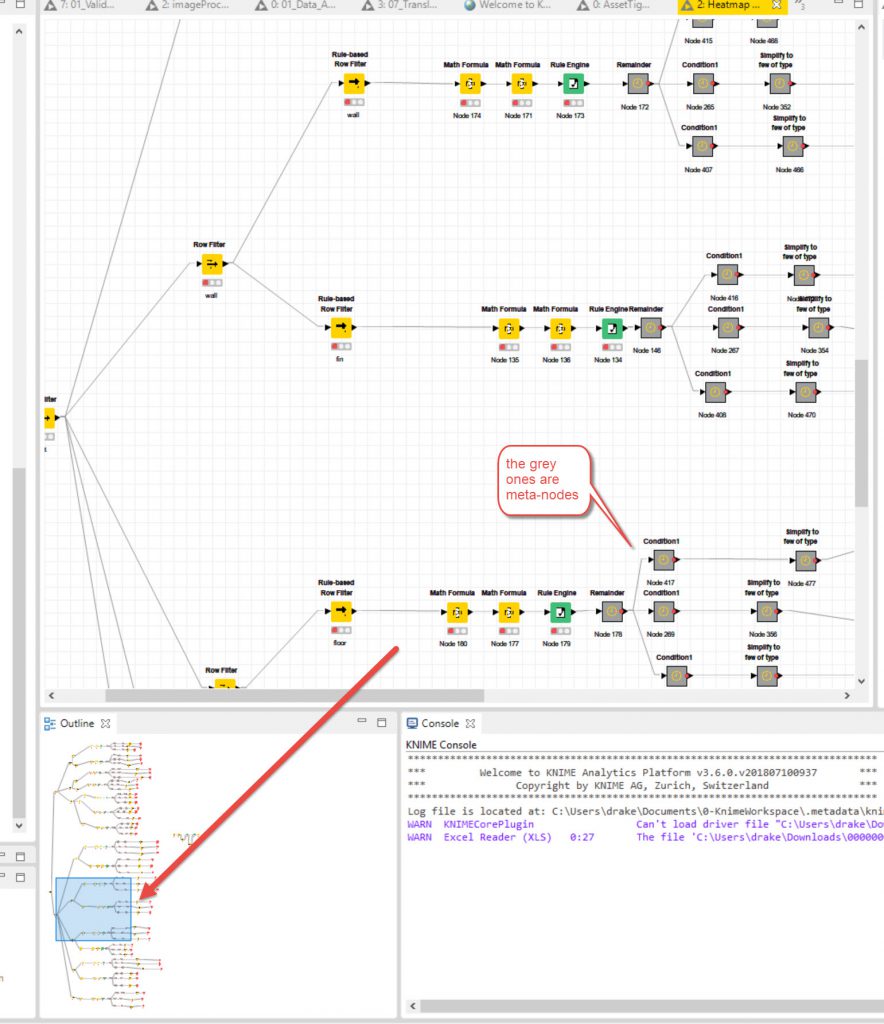
This is one of the meta-nodes expanded showing each separate node within (52 nodes). You can then copy these meta-nodes to the processes below.

End Comment
Once your process is built it is pretty robust. I prefer this to Excel where its easy to delete something from a cell, and if that ids a formula that can cause chaos.
I have found that once I have developed some of the processes they are easy to use later. Also I have adapted them for other processes.
I want to start testing the machine learning processes, that will be on my list of things to do soon.
PSPP, free tool for statistical analysis also iNZight, SofaStatistics & Jamovi
Python Future prices, WITS API & My Electricity Bill