Orange 3. Text Mining basic exploration
A few words of jargon in the Text Mining area.
- Corpus. In linguistics, a corpus or text corpus is a large and structured set of texts. They are used to do statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory.
- Token. Tokenization is the process of demarcating and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input.
There are 4 videos that I watched relating to this post, they are:
The Text Mining is another Add-On so you have to fire up Orange as the administrator then you can download it.
Some features of Orange Text Mining Tab
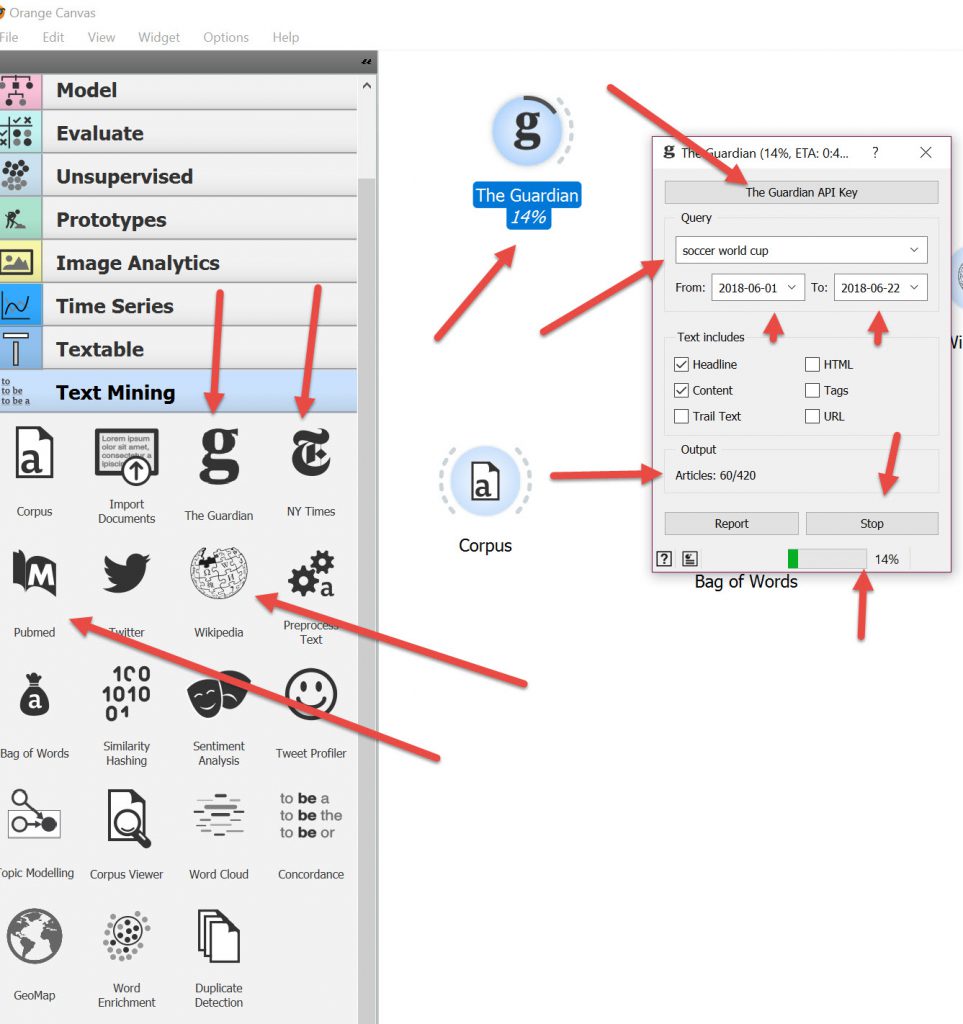
There are a couple of other features that were not noted in the videos on text mining. There are links to The Guardian, The NY Times, PubMed, Twitter & Wikipedia for linking to data.
PubMed is a free search engine accessing primarily the MEDLINE database of references and abstracts on life sciences and biomedical topics.
You can link to Wikipedia for getting data, or Twitter ( I do not have an account so not much interest to me).
The Guardian & NY Times are pretty obvious. You do need an API key to be able to use the plug in. For the Guardian, if you are using it for personal use the API key is free, just fill in the form and they’ll send you it. You then need to type in your query,eg ” soccer world cup” select dates for bounding , choose Text to include Headlines, content, etc and the bottom right hand button is Search (when running its a STOP button) and then wait for the data to download.
There is the Corpus tool for pulling in data, or Import Documents , where you can select your own directories with TXT, Word, PDF docs to group together ( see video 4)
Then there is the Corpus Viewer that allows you to see the Data.
Preprocessing Text Node is really useful, allowing you to create a simple text file to add simple words, numbers, symbols etc and use this as a filter. You will note when using the Word Cloud that words like : The , And, Is, are the most common and need to be filtered out to make the word cloud meaningful.
Word Cloud very good for overview of word count and more common words.
Other methods for getting a more comprehensive data set would be to do some web scrapping to get a more varied sample of data on a topic. See this post.
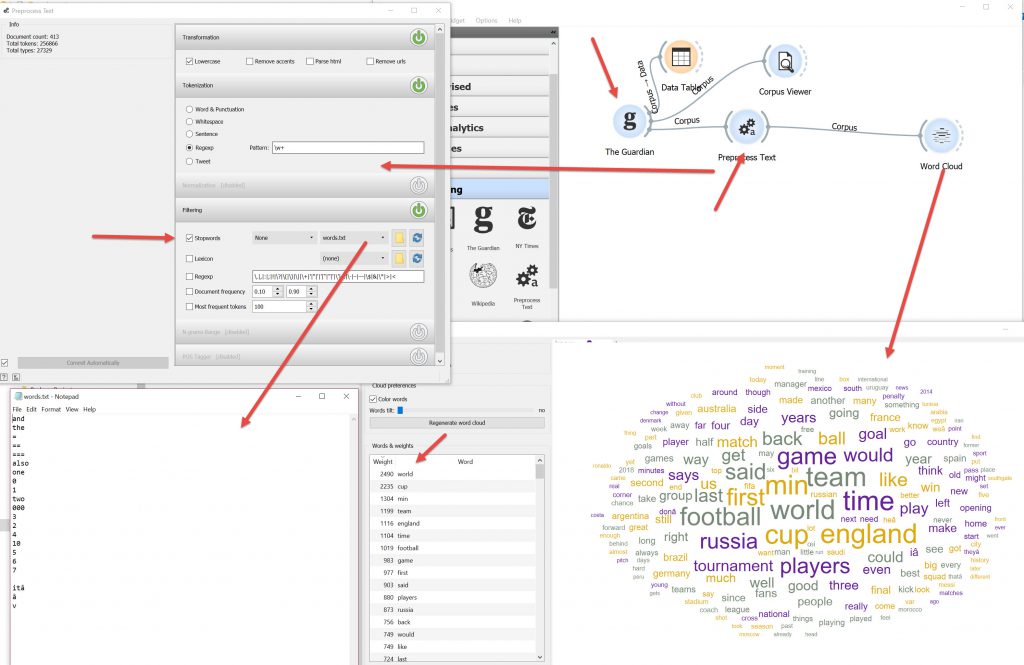
The word cloud and number count are interesting ways to visualise the data, but I’m not sure what use they are to me in my exploration of building assets.
I found the Regex was an important control for filtering, and you’d need to have some good resources to get that running well. I was having difficulty managing that but would explore it further the next time I wanted to use the text analytics tool.
I did have issues with odd text symbols, such as “€�” that came up. I found I had to go into the Corpus linked to the original input to find an example to cut/paste into the .TXT file for Stopwords in the preprocessing text widget.
End Thoughts
The text videos are a good demonstration of how to use the Text processing for classification and testing new documents to see which classification they fall into.
There seems to be a bit of preparation for those documents prior to running the machine learning with bag of words/distance/hierarchical clustering and logistic regression.
I just wanted a short play with the tool. One thing I noted was it processes single words but trying to get other groupings (2 to 3 word clusters for something like “United States, rather than “United” or “States”) was a bit of a challenge. It could easily do sentences, but each would be unique so there would be minimal clustering on that scale. I think there is a bit more to the text analytics and I’d need a better understanding of it before I give the process another try.
There were not too many videos to follow apart from the main example. A bit more research is required on my part.
I noted that Knime also has a twitter connector & after setting up access to a Twitter Developers Account you can access their API’s. Here is a post on a pretty similar process to the Orange process using Knime. A few more steps along the way, but possibly more controllable.
I have tested
Asset Tiger 3. Testing features Linking, Photo’s, Documents, STATUS Broken/Repaired, Alerts & Mobile App

WordPress site- relocating links on another site
