Finding leads for my Services Website- web scraping? Part 2
Well, its never as simple as what is shown in the videos. This post follows on from my earlier post part 1. This time I try running through the process and getting a workflow going.
1. Google Trends
I did play with this a bit an terms that started popping up were “Computer-aided facility management” and “Computerized Maintenance Management System”. So I used this as a starting process for my search.
2. Search in Chrome & Email Extractor
I ran the process of searching using as search the following:
- “Computer-aided facility management” + gmail.com (hotmail, outlook) and “CAFM”+ gmail.com (hotmail, outlook)
- “Computerized Maintenance Management System” + gmail.com (hotmail, outlook) and “CMMS”+ gmail.com (hotmail, outlook)
Then gathered about 650 odd email addresses using the Chrome plug-in Email Extractor and sent them to a CSV (comma Separated Value) file.
3. Dr Email Verifier and export to file
I only used gmail.com (hotmail, outlook) to search for as Dr Email Verifier actually checks these ones, unlike yahoo.com that it just assumes it is OK as it is on an unsupported server for the programme.
I then tried to validate the emails , uploading the file a number of times , after adjusting the preset to allow upload of 700 odd files so that I could load batches of 20 at a time. I had 400 all loaded in the programme and then ran the “Verify All” button and let it get on and do its work. There were an awful lot of “checking failed’ and suggested “recheck” but this did not change the outcome.
Not all the emails were gmail.com, hotmail.com or outlook.com, so some slipped through as “Unsupported server, marked as OK“.
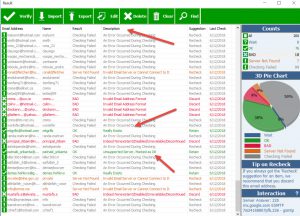
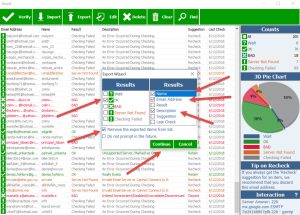
Because of the “Unsupported server, marked as OK” getting through, on the export file I also included the description column, that way I could filter it later.
4.Cleaning data in Excel
On export it creates a file with no extension so I renamed it .CSV and opened it in Excel, then I could filter the columns to find the “Unsupported server, marked as OK” rows and delete them.
Then I had the issue of blank rows in my spreadsheet. Look at this article on how to get rid of blank rows. I’d always done it manually in the past and that was a pin. This is a far more elegant method.
So now I have the verified email addresses. First I deleted the Description column, I dson’t need it anymore. Then I copy the email column across to the adjacent column and use Find/Replace on one of the columns using:
find: @*.*
replace: (leave blank)
Then replace all of the selected column.
I renamed this column : name
The Email address column I renamed: email
You need to be aware of column titles for the Mail merge tool in Thunderbird or nothing happens. This happened on a few occasions.
I also ran a “REMOVE DUPLICATES” button on the selection (under the Data Tab in Excel). At the end I had 126 valid email addresses. That was starting out with over 650.
I also saved the file with only a couple of email addresses in the file to use as a test file to send to Draft.
There is an opportunity here to get a process going with Knime for taking information and converting it into the structure that you require for the next part. You need the Validated Emails then you could plug it into a KNIME WORKFLOW and have it spit out a formatted CSV file for Thunderbird Mail Merge. I need to do this a number of times before its worth implementing.
I’m also wondering if there is an opportunity to use CODA.IO in a way to do some of the processing? Things may become clearer with repetition.
5.Thunderbird, templates and Mail Merge
“ A rose by any other name will smell as sweet” Shakespear’s Romeo and Juliet.
You would think a file with an extension .CSV would be a Comma Separated Value file. Well, that is not the case. Like hell it is!!!! Even after the file was opened and modified in Excel and saved to a .CSV.
I spent a fruitless hour trying to get my mail merge test to work but the test file data was not Comma Separated!
So the process of hopping between different programmes can somehow reformat the file so it is not a Comma Separated Value file. And just saving in Excel to a .CSV does not change that. You can, with the file open, EXPORT and choose FILETYPE and select CSV then it “MAY” change to a CSV format with commas between data fields. I found the issue in this article.
What I would suggest, in your workflow, is when you have your emails verified and the description field cleaned out and the name field created then save the file & open it in either “Notepad” or “Notepad++” and view the file. If there are commas between the fields then all is good, if not then you have to get them there. Maybe use an online converter, or save as an Excel xlsx file and then re-save as CSV.
I ended up going back a couple of steps and re-started the gathering of the information, checking to see that the file was in REAL CSV format. A bit tedious but I’ll check the workflow next time.
Using a previously used template was not too much of an issue, just a matter of right clicking on the template that you want to use and then clicking on “New Email from Template”. It took me a bit of looking around to get that to work.
After selecting the template I then used the mail merge tool (as per the previous post on this subject) and tested the Test File with a couple of emails sent to DRAFT. Then I could check the output emails to see if they were alright. This was the point where I found the issue with the CSV file. I actually unloaded the Mail Merge Add-in and reloaded it again into Thunderbird.
I had 2 mail failures from the 126 emails. That is far better than the previous effort.
At this point i sent the 126 emails out. It took 15 minutes for it to run. I will now delete these files from my SENT folder and keep the file with the email addresses in a separate marketing folder.
6.Keywords
One of the videos I watched recommended using keywords and to use the Google Keyword Planner Tool. This is part of Google Ads and you need to log in with a gmail account but you only need to go as far as the keyword section to get popular key search words.
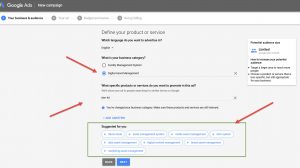
At this point I’ve just put the ones I chose in tags, but will need to go back and add them to some of the services content sometime.
End thoughts
Its nice to set up a process and find the bugs and resolve them so that there is a logical workflow. This can, over time, get more refined. But at least there is an iterative process to follow.
Big picture. I have a new website displaying some services that i want to offer. I need people to visit that website to see what is there.
Strategy? Email people who may have some interest in the services. Hopefully someone make further enquiries.
Process?
Part 1.Initially broad targeting. You are only really harvesting personal emails with searches which include gmail.com etc. But because these are easier to harvest it is better to get the information out there to a wider group, maybe some people will pass it on to someone who is interested.
I’m not sure of the statistics of this process, whether it is 1% reaction or .1% 0 or 0.01%. I’m sure its low. Anyway all I can do is plug away at this and see if I can refine the search. Also do a bit of research to gain a better understanding of the process. One can only travel the road and find out.
Part 2. After using the blunt instrument a more targeted approach needs to be taken. I need to find some Facility Management Directories and do a web crawl on some of those. It will take longer to set-up as its specific to the site but it’ll be more specific, identifying company email addresses instead of personal ones. This will be my next step. And a bit more fossiking also.
Part 3. If I do get some leads I suppose I could do a MailChimp drip marketing process. Although the last one I set up was not at all successful. But that is for another day.
I need to send something out into the ether to see what will happen.
So, phase 1 started. Now I have a few more key words I will do some more scraping based on those. This will garner more personal emails and I need to go back and read my post on web scraping specific sites. This will be a bit of Part 2./ I have a couple of sites I’m interested in trying the process out on.
Google Cloud SQL instance for Data Studio
Free Google Tour Creator with Street View or 360 camera panoramas